中间件性能挑战赛 比赛小结
上周参加中间件性能挑战赛,赛题的大致意思就是充分利用多核CPU,看谁开发的程序最快。对于这类题目,语言的选择上就显得很重要,因为对于同样的算法,在都做了充分的优化的情况下,就剩下纯粹的比拼语言的执行效率了。
所以我选择了用go,可能有些同学还不太了解,首先看一下go语言的显著的几个特点:
- 和c\c++一样都是编译型语言,直接编译成本地机器码执行,官方所说执行效率逼近c
- 语言自带垃圾回收,编译时编译进运行时
- 语言内建协程,以非常廉价的方式实现并行
- 编程多范式支持,可以既面向过程又面向对象,还可以函数式编程
下面简单说一下我的思路:
- 我使用的字典树的数据结构,这种数据结构对于小文本的来说是比较有利的,后面换成大文本,字典树就有些力不从心了。基本结构就是一个节点代表一个字符,里面包含从这个节点向上遍历形成的单词的count。
type CharTreeNode struct {
Count int
Children [26]*CharTreeNode
}
-
总体的流程图是:
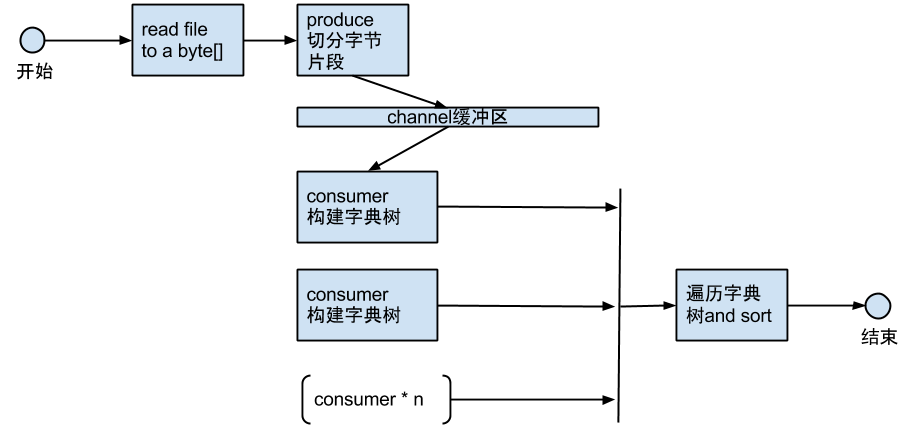
-
申请一个很大的byte数组,一次性把文本读入内存。这个时间没什么好优化的了,因为即使是1.1G的文件,这个时间大约是600多ms。
-
多协程构建字典树。引入生产者消费者模型,有生产线程不断从byte数组中拆分byte片段,这里的拆分需要注意的是不能把一个单词拆分成两半。
然后把拆分出来的byte片段的指针不断放到缓冲通道里去,同时会启动和cpu核数相当的消费者协程不断从缓冲通道里消费byte片段。
消费者协程共享同一棵字典树,一旦拿到byte片段,就调用构建字典树的方法。这里为什么采用这样的方案是因为,最初可以分为cpu核数 大的byte片段,然后每个线程分别去构建这几个大的片段,这时会发现,分割的粒度太粗,每个协程构建字典树的时间差异很大,有的很快完成,有的会慢一些。那么最终的总耗时时间会由最慢的协程决定。所以引入生产者消费者来达到使分割的粒度足够小,每个协程的构建时间能比较平均,最后总的耗时会整体变小。这里也是利用了go语言的高效并发通信的优势,go内建了协程间的通信通道,不同执行体之间的通信不像java一样采用共享内存的方式,而是采用erlang的方案,通过语言提供的高效通信通道来通信,换用go的话说就是Do not communicate by sharing memory; instead, share memory by communicating。通过这样的优化确实能达到各个执行体的耗时比较平均,总体的提升有1秒多的样子,但是依然是主要耗时任务,这个过程差不多就要3s了。
-
等待所有协程构建字典树完成,然后遍历字典树,count的值大于1的节点向上遍历就可以形成一个单词,然后把单词和他的count插入到一个长度固定的排序的链表,就可以拿到最后的结果。这个遍历字典树和排序的过程会总共耗时30~40ms。
-
所有消费者线程共享构建同一棵字典树,其中CharTreeNode中的count会更新非常频繁,为保证线程安全使用了和java中的AtomInteger同样的方式:atomic.AddInt32(¤t.Count, 1)。CharTreeNode另外的成员变量Children,在对某一个child赋值的时候同样存在线程安全问题,不过在所有的构建字典树协程同时对同一个节点的同一个child赋值的情况并不多,这里采用了加锁的方式保证线程安全:
lock := &sync.Mutex{}
lock.Lock()
current.Children[offset] = new(CharTreeNode)
lock.Unlock()
因为执行到这里代码块的概率非常小,我做过实验,去掉加锁,对结果的准确性和耗时的影响都微乎其微。
比赛总结
所以上面的主要四个过程,可以说构建字典树占用了绝大多数的时间。这也就是文本开始是20m大小时,比较快的几个中有好多字典树的方案,到后面使用1G的文本时,他们多消失不见了。字典树这种结构个人感觉比较适合于小文本的情况,文本越大,它的劣势也就越明显。粗略估计,问题在于,字典树以字符为维度统计,而map以单词为维度统计。例如,一个小文本,可以共有100w个字符、2w种单词,比例为50;一个大文本,字符共有10000w个,单词可能是4w种,比例为2500。所以文本越大map就会相对越节省时间。
语言的选择固然重要,所以看到前五名都是c++。但是现代语言都已经很成熟,运行效率相差不大的情况下,采用的数据结构和算法才是决定因素。