计算地图上一个点附近的点的两种方法
随着移动终端的普及,LBS的应用慢慢增多起来,比如附近的人功能成了陌陌微信等im的标配,以及大众点评的附近的餐馆、酒店等。
通过一个点的gps信息找出它附近的点,就是上面这样功能的核心。通常有两种实现方法,各有优缺点,需要根据场景不同选择适合的。
一、geohash + sql数据库
-
首先按照地址的经纬度按照下图的方法得出0101的编码,编码位数越多,描述地址的精确度越高。具体方法是:先计算维度,范围(18.09, 53.33)平分成两个区间(18.09, 35.71)、(35.71, 53.33), 如果目标纬度位于前一个区间,则编码为0,否则编码为1。由于39.92324属于(35.71, 53.33),所以取编码为1。然后再将(35.71, 53.33)分成 (35.71, 44.52), (44.52, 53.33)两个区间,而39.92324位于(35.71, 44.52),所以编码为0。以此类推,直到精度符合要求为止,得到纬度编码为1011 1000 1100 0111 1001。
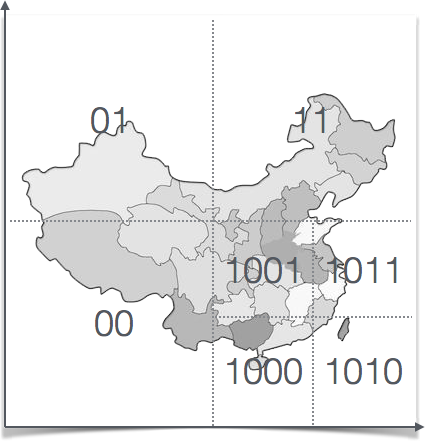
-
然后再对得出的类似这种形式的地址11100 11101 00100 01111 00000 01101 01011 00001进行base32编码,用0-9、b-z(去掉a, i, l, o)这32个字母进行base32编码,得到(39.92324, 116.3906)的编码为wx4g0ec1,这个就是地址的geohash值。
-
可以把编码之后的地址数据放入数据库,以geohash字段建索引。
-
查找一个点附近的店就可以通过这种方式,sql数据库:SELECT * FROM address WHERE geohash LIKE 'wx4g0%'。wx4g0代表的是地图上一个正方形的块,如下图阴影选择的区域。

二、经度、维度取交集 + 内存排序
- 保存地址数据的时候,冗余一个城市的字段
- 系统启动时加载所有的地址点到内存
- 以城市对数据分片,每个城市内分别建立经度、纬度上地址点的索引,使用TreeMap保存
- 给出一个经度120.024082,计算附近1000m以内的点,比如:事先计算好的1000m距离的经度差是0.01042,那么就可以查询在[120.018872, 120.029292]范围内的点,同样的方法,查询到纬度距离1000米以内的点
- 然后取两个集合的交集,如果取得的交集是空,那么可以重复步骤2,扩大查找范围到1000m*5,再次查询经度、纬度上的点,然后再取交集
- 取得交集后的点就是图中以红点为中心,正方型圈出来的点,然后计算与红点的具体距离,距离计算公式可以参考这篇文章里的算法
- 然后对交集里的点按距离排序,就能够得到按照距离排序后的点了
- 为什么按照城市分片是因为,如果在全国范围内构件经纬度的索引,查询一个点附近的点,这个跨度就会很大,可能1000m内纬度距离内的点就会遍布在内蒙古和海南,这就会把距离很远的点也列入附近的点考虑的范围,实际取交集后重合的点却很少。所以一种优化的做法是,按照城市的维度分别构建经度、纬度的map。给出一个点时首先根据经纬度计算出它所在的城市,然后在城市的范围内查找,这样取交集成功的机会就会大很多,查找效率会提高不少

优缺点比较:
- geohash
- 优点:
- 可以支持地址点的位置信息变化的情况,需要更新数据库里地geohash字段
- 数据量小时,数据库很好的承接了附近点的计算
- 缺点:
- 特殊情况时计算的附近的点不准确,比如正好处于正方形边缘的点
- 需要提前计算geohash值,并持久化到数据库中
- 数据量增多,like查询会变慢,数据库查询、写入压力大,容易形成单点
- 开发成本较高
- 优点:
- 内存计算
- 优点:
- 计算附近的点相对准确
- 开发成本低,不需要额外建表
- 可以通过不同机器加载分片的数据,解决数据量大的问题
- 缺点:
- 需要系统启动时加载数据并构件经度、纬度上地址点的索引,在构建完索引之前,是没法提供服务的
- 地址点的位置信息不能改变,对于经常变化位置的场景需要采用geohash
- 对于两个属于不同市的相距很近的点是计算不到的,这个需要根据场景取舍,此方法适用于附近的餐馆、银行等场景,因为它们有极大可能处在同一市内,而不适用于周围的人
- 优点: